CHAPTER 15. Collection Framework이전 포스팅에서 java.utill 패키지에서 제공하는 Generic에 대해서 알아보았습니다. 오늘은 Collertion Framework(컬렉션 프레임워크)에 대해 알아봅시다!!
1 ) Collertion Framework란?
자바에서 Collertion Framework란 다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합을 의미합니다. 배열은 크기가 고정되어 있는 데에 반해, 컬렉션 프레임워크는 가변적인 크기를 갖는(Resizabla)등의 특징이 있고, 데이터 삽입, 탐색, 정렬 등 편리한 API를 다수 제공합니다.
즉 데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현해 놓은 것입니다.
2 ) 주요 인터페이스
컬렉션 프레임워크에서는 데이터를 저장하는 자료 구조에 따라 다음과 같은 핵심이 되는 주요 인터페이스를 정의하고 있습니다.

※ 이 중에서 List와 Set 인터페이스는 모드 Collection 인터페이스를 상속받지만, 구조상의 차이로 인해 Map 인터페이스는 별도로 정의됩니다!! 따라서 List 인터페이스와 Set 인터페이스의 공통된 부분을 Collection 인터페이스에서 정의하고 있습니다.
2-1 ) 주요 인터페이스의 특징
| 인터페이스 | 설명 | 구현 클래스 |
| List<E> | Index 순서로 요소를 저장하고, 중복된 데이터를 저장할 수 있습니다. | Vector, ArrayList, LinkedList, Stack, Queue |
| Set<E> | 순서가 없으며, 데이터를 중복으로 저장할 수 없습니다. 집합 연산(합집합, 교집합, 차집합 등)을 지원합니다. | HashSet, TreeSet |
| Map<K,V> | Key-Value 쌍으로 데이터를 저장합니다. 순서가 존재하지 않으며, Key가 중복될 수 없습니다. | HashMap,TreeMap,Hashtable, Properties |
3) List interface 구현
List interface는 대표적인 선형 자료구조로 주로 순서가 있는 데이터를 목록으로 이용할 수 있도록 만들어진 인터페이스 입니다. 좀 더 쉽게 얘기하면 우리가 지금까지 사용했던 배열에서 int[] array= new int[10]; 처럼 사용합니다. 하지만, 이 처럼 선언한 배열의 경우에는 10개의 공간 외에는 더 이상 사용하지 못하기 때문에 이러한 단점을 보완하여 List를 통해 구현된 클래스들은 "동적 크기"를 갖으며 배열처럼 사용할 수 있게 되어 있습니다.
그럼 예시를 통해서 알아봅시다.
List<String> lst1 = new ArrayList<>();
lst1.add("111");
lst1.add("222");
lst1.add("333");
lst1.add("444");
System.out.println(lst1);
int size = lst1.size();
System.out.println("size = "+ size);
for(int i =0; i<size; i++){
System.out.println(i +"번째="+lst1.get(i));
}
위 코드는 lst1 안에 add() 메서드를 사용하여 4개의 요소를 추가했습니다. 그럼 출력해보면 0번째는 "111" 1번째는 "222" 등 순차적으로 출력이 되는데 하지만 중간에 요소를 삽입해야 하는 상황이 발생할 수 있다.
그럴 땐 어떻게 해야할까요?? 요소들을 한 칸씩 밀어버리면 됩니다. 그전에 출력 값을 확인해 보면 아래 사진과 동일하게 나옵니다.

그럼 순차적으로 담겨져 있는 요소들 중간에 다른 요소를 삽입을 해야 한다면?? index 값과 요소를 같이 구현하면 됩니다.
index는 내가 몇번 자리에 추가하고 싶은 지 확실하게 선언해야 합니다.
List<String> lst1 = new ArrayList<>();
lst1.add("111");
lst1.add("222");
lst1.add("333");
lst1.add("444");
lst1.add(1,"100"); // index :1 , element : 100
System.out.println(lst1);
}
위 예시는 중간의 요소를 삽입하는 과정을 보여주는데 그럼 반대로 삭제해야 하는 경우가 있습니다. 그럴 땐 반환 타입인 boolean을 선언하면 되는데 저는 "100"을 다시 삭제하려고 합니다. 그렇다면 이렇게 지정한 객체가 있다면 메서드는 어떤 걸 사용하면 될까요??
바로 remove() 입니다. 확실하게 삭제가 되었는지 알기 위해서 삭제가 되었다면 true가 출력되게 코딩을 해봤는데 방법은 다음과 같습니다.
boolean ispop= lst1.remove("100");
System.out.println("ispop = "+ ispop);
System.out.println(lst1);
"100"이라는 값이 완벽하게 삭제가 됐다면 ispop = true 가 출력이 됩니다. 결과는 다음과 같습니다.

또한 지정된 객체가 아닌 그 뒤의 요소들을 삭제해야 하는 상황이 있으면 remove() 메서드를 활용해서 요소들을 삭제할 수 있습니다.
String pop= lst1.remove(1);
System.out.println("pop = "+ pop);
System.out.println(lst1);위 코드에서 1은 index 값으로 1번째 요소를 삭제를 하겠다고 선언을 했습니다. 요소가 삭제가 되었다면 pop = 1번째 요소가 출력이 되면서 1번째 요소가 빠진 자리는 한 칸씩 당겨지는 걸 확인할 수 있습니다.

<List interface 구현하는 클래스 생성 방법>
List<T> arraylist = new ArrayList<>();
List<T> linkedlist = new LinkedList<>();
List<T> vector = new Vector<>();
List<T> stack = new Stack<>();
4 ) Stack & Queue
- Stack이란 자료구조는 책을 쌓는 것처럼 차곡차곡 쌓아 올린 형태의 자료구조를 말합니다. 같은 구조와 크기의 자료를 정해진 방향으로만 쌓을 수 있고, 가장 마지막에 삽입된 자료가 가장 먼저 삭제된다는 구조적 특징을 가지고 있습니다.(LIFO)
- Queue란 주로 데이터가 입력된 시간 순서대로 처리해야 할 필요가 있는 상황에 이용합니다. 예를 들어 사전적 의미로 " 무엇을 기다리는 사람, 자동차 등"줄, 혹은 줄을 서서 기다리는 것을 의미합니다. 그래서 큐는 한쪽 끝에서 삽입 작업이, 다른 쪽 끝에서 삭제 작업이 양쪽으로 이루어집니다. (FIFO)
Stack & Queue에 대해서 좀 더 알아보자면 아래와 같습니다.

그럼 예시를 통해서 알아보자.
ArrayList를 사용하여 Stack(LiFO)을 구현하시오.
ArrayList를 사용하여 Queue(FiFO)를 구현하시오.

먼저 변하지 않는 값은 배열에 담아주고 Stack을 먼저 구현해 보자.

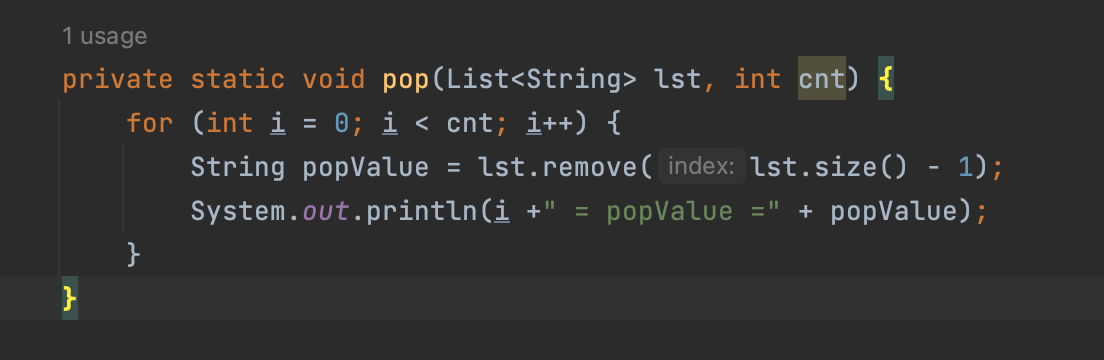
Stack의 자료구조를 알아보기 전에 lst에 strs[i]값을 넣어주고 for문을 사용하여 초기 값이 잘 들어갔는지 확인을 해볼 수 있습니다. Stack은 LiFO 자료구조라서 마지막에 들어간 값 "ccc" 가 0번째로 들어와야 "정상적으로 출력했구나" 알 수 있습니다.
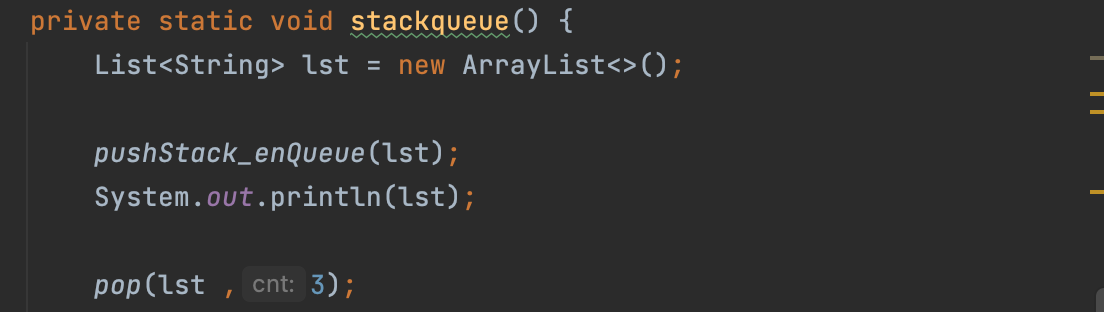

위 예시를 보면 정상적으로 Stack의 자료구조에 대해서 확인할 수 있는데, 처음 배열에 담았던 "aaa"가 처음으로 나올 수 있는 구조입니다. 그럼 cnt 값을 '2' 로 수정하고 결과를 확인해 보자.
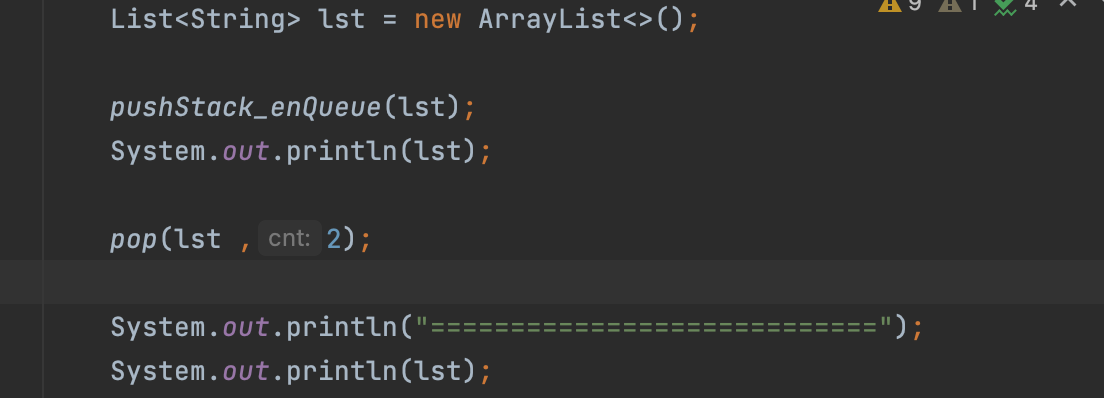

그렇다면 Queue 자료구조 방식도 확인해 보자. 동일하게 for문을 활용했습니다.


Stack과 동일하게 고정 값 3개 모두 출력되는지 확인해볼 수 있는데 Queue는 FiFO 형식이기 때문에 0번째 자리가 "ccc"가 아닌 "aaa"가 출력되어야 합니다.

출력된 값을 보면 Queue 방식은 순차적으로 처리하는 방식이구나 라는 걸 알 수 있습니다. 그럼 cnt 값을 '2' 로 주면 순차적으로 처리하는 구조라서 "ccc"가 출력되는 걸 알 수 있습니다.

< List Interface에 선언된 대표적인 메서드 >
| 메서드 | 리턴 타입 | 설 명 |
| add(E e) | boolean | 요소를 추가합니다. |
| remove(Object o) | boolean | 지정한 객체와 같은 첫 번째 객체를 삭제합니다. |
| contains(Object o) | boolean | 지정한 객체가 컬렉션에 있는지 확인합니다. 있을 경우 true, 없을 경우 false를 반환합니다. |
| size() | int | 현재 컬렉션에 있는 요소 개수를 반환합니다. |
| get(int index) | E | 지정된 위치에 저장된 원소를 반환합니다. |
| set(int index, E elemanes) | E | 지정된 위치에 있는 요소를 지정된 요소로 바꿉니다. |
| isEmpty() | boolean | 현재 컬렉션에 요소가 없다면 true를, 요소가 존재한다면 false를 반환합니다. |
| equals(Object o) | boolean | 지정된 객체와 같은지 비교합니다. |
| indexOf(Object o) | int | 지정된 객체가 있는 첫 번째 요소의 위치를 반환합니다. 만일 없을경우 -1을 반환합니다. |
| clear() | void | 모든 요소들을 제거합니다. |
5 ) Set interface 구현
Set은 말 그대로 '집합'입니다. Set의 가장 큰 특징이라 하면 크게 두 가지 있는데, 첫 번째로 " 데이터를 중복해서 저장할 수 없다"이고,
두 번째는 "입력 순서대로의 저장 순서를 보장하지 않는다"입니다.
그럼 예제를 통해서 알아봅시다.
이전 포스팅에서 사용했던 Student 클래스에서 hashCode 값을 id값만 return 선언하고 코드 작성을 했습니다. 아래와 같습니다.

private static void sets() {
Set<Student> set = new HashSet<>();
set.add(new Student(100,"Hong"));
set.add(new Student(50,"Lee"));
set.add(new Student(200,"Kim"));
System.out.println(set);
hashCode 코드에서 id값만 return 하겠다고 선언한 이유는 위 코드를 보면 id 값이 100,50,200 이렇게 무작위로 추가했습니다. 그렇다면 결과는 동일하게 100,50,200 값이 나올까?? 결과는 아래와 같습니다.
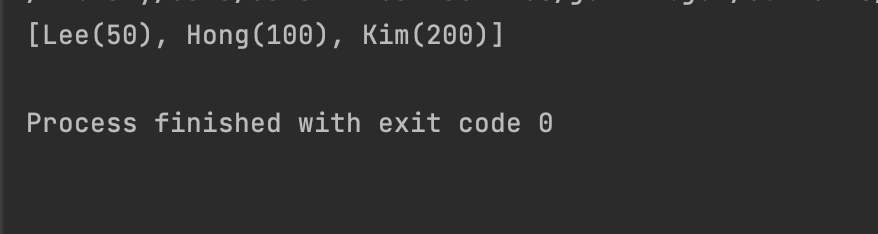
출력을 해보니 id값이 적은 순서대로 출력이 되었습니다. 왜 그럴까?? 그건 바로 hashCode()와 equals()로 판단을 하는데 lee의 id값이 나머지 값보다 낮기 때문입니다.
그렇다면 중복된 값을 넣으면 어떻게 될까??
private static void sets() {
Set<Student> set = new HashSet<>();
set.add(new Student(100,"Hong"));//1
set.add(new Student(50,"Lee"));
set.add(new Student(200,"Kim"));
set.add(new Student(100,"Hong"));//4
System.out.println(set);
}
(100, "Hong")이라는 값을 add() 메서드를 활용하여 요소를 추가해 봤습니다. 결과는 아래와 같습니다.
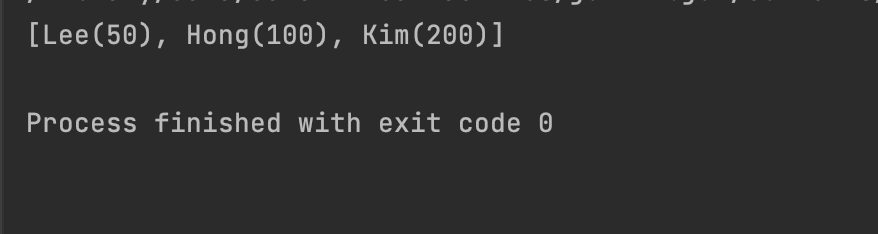
추가했던 요소는 출력이 되지 않고 동일한 값을 출력했는데, 이처럼 Set의 가장 큰 특징은 중복되는 데이터를 넣지 못한다는 점입니다.
<Set interface 구현하는 클래스 생성 방법>
Set<T> hashset = new HashSet<>();
Set<T> linkedhashset = new LinkedHashSet<>();
Set<T> treeset = new TreeSet<>();
<List Interface에 선언된 대표적인 메서드>
| 메서드 | 리턴 타입 | 설 명 |
| add(E e) | boolean | 지정된 요소가 없을 경우 추가합니다. 이미 지정된 요소가 존재하는 경우 false를 반환합니다. |
| contains(Object o) | boolean | 지정된 요소가 Set에 있는지를 확인합니다. |
| equals(Object o) | boolean | 지정된 객체와 현재 집합이 같은지 비교합니다. |
| isEmpty() | boolean | 현재 집합이 비어있을 경우 true를, 아닐경우 false를 반환합니다. |
| remove(Object o) | boolean | 지정된 객체가 집합에 존재하는 경우 해당 요소를 제거합니다. |
| size() | int | 집합에 있는 요소의 개수를 반환합니다. |
| clear() | void | 집합에 있는 모든 요소들을 제거합니다. |
| first(E e) | E | 첫 번째 요소(가장 낮은 요소)를 반환합니다. |
| last() | E | 마지막 요소(가장 높은 요소)를 반환합니다. |
| headSet(E toElement) | SortedSet<E> | 지정된 요소(toElement)보다 작은 요소들을 집합으로 반환합니다. |
| tailSet(E fromElement) | SortedSet<E> | 지정된 요소(fromElement)를 포함하여 큰 요소들을 집합으로 반환합니다. |
| subSet(E from, E to) | SortedSet<E> | 지정된 from요소를 포함하여 form보다 크고, 지정된 to 요소보다 작은 요소들을 집합으로 반환합니다. |
마치며
배열의 단점을 보완하고 객체나 데이터들을 효율적으로 관리하려고 사용하는 게 컬렉션 프레임워크입니다. 배열은 생성할 때 크기가 정해지고 그 크기를 넘어가면 데이터를 저장할 수 없기도 하고, 또한 데이터가 비어있으면 메모리가 낭비된다는 단점이 있습니다.
이러한 단점을 보안하고자 컬렉션 프레임워크를 사용합니다.
'[ JAVA ] > JAVA' 카테고리의 다른 글
| [ Java ] 내부 클래스(Inner Class) (0) | 2023.01.03 |
|---|---|
| [ Java ] Scanner (0) | 2022.12.29 |
| [ Java ] Generic (0) | 2022.12.26 |
| [ Java ] JDK 기본 클래스 2 (0) | 2022.12.25 |
| [ Java ] JDK 기본 클래스 1 (0) | 2022.12.22 |



