
Intro
안녕하세요. 환이s입니다 👋
앞선 글에서는
Docker와 Kubernetes가 왜 같이 쓰이는지,
그리고 애플리케이션이 어떤 흐름으로 실행되는지를
하나의 그림으로 정리해봤습니다.
이번 글에서는
그 흐름을 조금 더 안쪽으로 들어가서
Kubernetes 내부 구조가 어떻게 생겼는지를 살펴보려고 합니다.
여기서도 마찬가지로
실습은 없습니다.
“이걸 어떻게 만들지?”보다는
“아, 그래서 이렇게 나뉘어 있구나”
이 감각을 먼저 잡는 게 목표입니다.
1. Kubernetes Cluster의 기본 구조
Kubernetes는
여러 대의 서버를 하나의 시스템처럼 묶어서 관리합니다.

그중 한 대는
전체를 관리하는 마스터 역할을 하고,
나머지 서버들은
실제로 애플리케이션이 돌아가는 노드 역할을 합니다.
이렇게 묶인 하나의 묶음을
Kubernetes 클러스터라고 부릅니다.
여기서 중요한 포인트는 이겁니다.
자원이 부족해지면
서버 한 대를 업그레이드하는 게 아니라
노드를 하나 더 붙입니다.
쿠버네티스는
처음부터 “여러 대를 쓰는 걸 전제로” 만들어진 시스템입니다.
2. Namespace - 논리적인 공간 분리
클러스터 안에는
Namespace라는 개념이 있습니다.

이걸 한 줄로 말하면
“같은 쿠버네티스를 나눠 쓰는 공간”입니다.
서비스별로 나누기도 하고
개발/운영 환경을 나누기도 합니다.
각 Namespace 안에는
Pod, Service 같은
Kubernetes 오브젝트들이 들어갑니다.
중요한 점은
서로 다른 Namespace에 있는 Pod들은
기본적으로 직접 접근하지 않습니다.
논리적으로 분리된 공간이라고 보면 됩니다.
3. Pod는 실행 단위이고, 컨테이너를 감싼다
Kubernetes에서
애플리케이션이 실제로 실행되는 단위는
컨테이너가 아니라 Pod입니다.

Pod 안에는
하나 이상의 컨테이너가 들어갈 수 있고,
각 컨테이너는 하나의 애플리케이션을 실행합니다.
그래서 결국
앱 → 컨테이너
컨테이너 → Pod
이런 구조로 감싸져 있다고 보면 됩니다.
근데 여기서 한 가지 문제가 생깁니다.
Pod는
언제든지 죽을 수 있고
언제든지 다시 만들어질 수 있습니다.
즉, Pod는 영구적인 존재가 아닙니다.
그래서 Pod 안에 데이터를 저장하면
Pod가 사라지는 순간
데이터도 같이 날아가게 됩니다.

이 문제를 해결하기 위해
Pod에는 Volume을 붙입니다.
데이터는 Pod가 아니라
Volume에 저장하고,
Pod는 언제든 갈아끼울 수 있게 만드는 구조입니다.
4. Service는 Pod 앞에 서 있는 창구다
Pod가 실행됐다고 해서
바로 외부에서 접근할 수 있는 건 아닙니다.
Pod는
IP가 바뀌기도 하고
개수가 늘었다 줄었다 하기도 합니다.
그래서 Kubernetes에서는
Service를 Pod 앞에 둡니다.
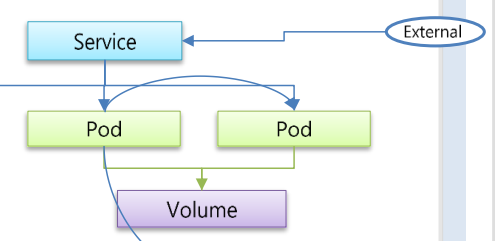
외부에서는 Service만 바라보고 접근하고,
Service가 알아서
뒤에 있는 Pod로 트래픽을 전달합니다.
Pod가 바뀌어도
접근 방식은 바뀌지 않게 만드는 역할입니다.
5. Namespace 단위로 자원을 제한한다
하나의 클러스터를 여러 팀이 같이 쓰다 보면
자원 문제가 생깁니다.

그래서 Kubernetes에서는
Namespace 단위로
쓸 수 있는 자원을 제한할 수 있습니다.
- Pod 개수
- CPU
- 메모리
이런 것들을
ResourceQuota와 LimitRange로 제어합니다.
6. Controller는 Pod를 대신 관리해주는 존재다
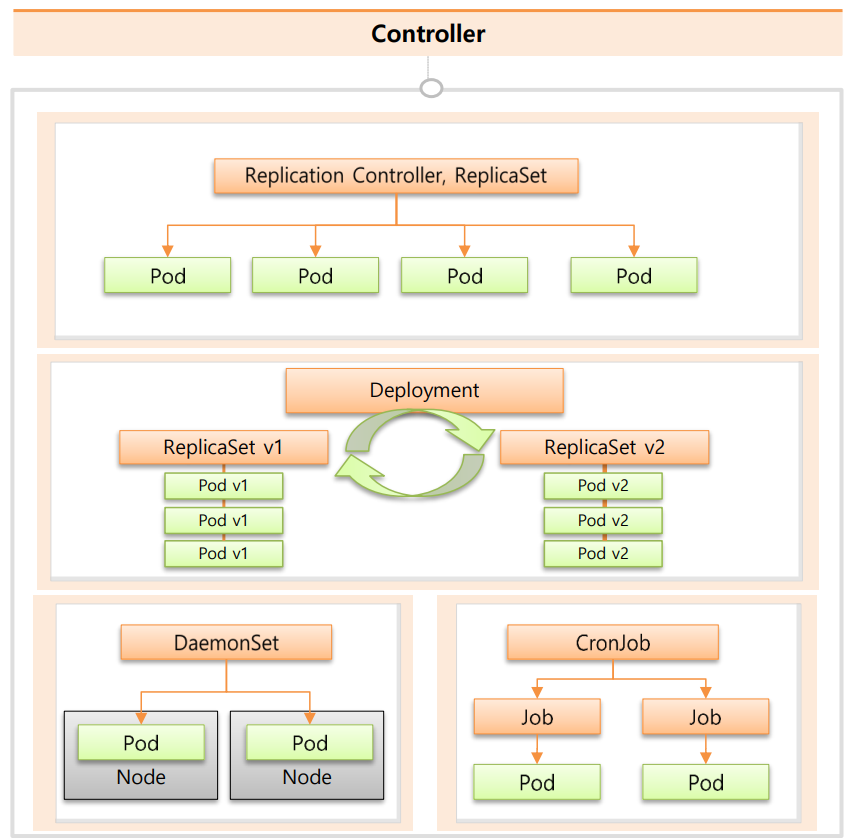
Kubernetes에서는
Pod를 사람이 직접 살리지 않습니다.
Controller가 계속 감시합니다.
Pod가 죽으면 다시 만들고
개수를 늘리거나 줄이고
상태를 원하는 모습으로 유지합니다.
가장 기본이 되는 컨트롤러가
ReplicaSet입니다.
7. Deployment는 배포를 책임진다
실제로 실무에서 가장 많이 쓰게 되는 건
Deployment입니다.
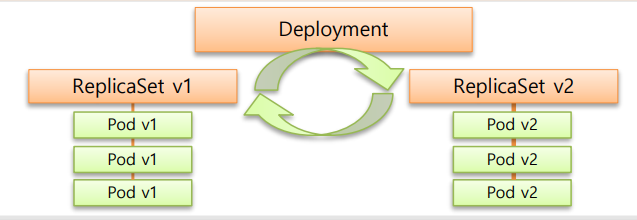
Deployment는
ReplicaSet을 관리하면서
- 버전 업그레이드
- 롤링 업데이트
- 문제 발생 시 롤백
이런 배포 과정을 책임집니다.
운영에서
“그냥 이거 쓰면 된다”에 가까운 존재입니다.
8. DaemonSet, Job, CronJob은 이런 상황에서 쓴다

DaemonSet은
각 노드마다 하나씩 꼭 떠 있어야 할 때 사용합니다.
로그 수집이나
모니터링 에이전트가 대표적입니다.
Job은
한 번 실행하고 끝나는 작업을 위해 사용합니다.
그리고 이 Job을
주기적으로 실행해야 할 때
CronJob을 사용합니다.
📝 마무리
이번 글에서는
Kubernetes의 내부 구조를
그림 기준으로 큰 흐름 위주로 정리해봤습니다.
아직은
각 오브젝트의 설정 방법보다
“왜 이런 구성인지”를 이해하는 단계입니다.
이 흐름이 잡히면
Deployment YAML이나 Service 설정을 볼 때
훨씬 덜 낯설게 느껴질 겁니다.
궁금한 점이나 추가로 다뤄줬으면 하는 내용이 있다면
언제든지 편하게 말씀해 주세요! 🙌😊
위 포스팅 글은 일프로님의 대세는 쿠버네티스(초급~중급편) 강의를 참고했습니다.
'[ Infra ] > Kubernetes' 카테고리의 다른 글
| [Kubernetes] Service - ClusterIP, NodePort, LoadBalancer (3) | 2026.03.18 |
|---|---|
| [Kubernetes] Pod - Container, Label, NodeSchedule (1) | 2026.02.04 |
| [Kubernetes] Getting started (0) | 2026.02.04 |
| [Kubernetes] VM vs Container (1) | 2026.02.03 |
| [Kubernetes] Why Kubernetes? (1) | 2026.02.03 |